给定一个字符串 S,找到 S 中最长的回文子串。
针对这个问题的解决方案很多。
在1975年的时候,一位叫做Manacher的人观察到查找回文子串的规律,创造出一种线性时间复杂度的算法,大幅优化回文子串查找效率。
这到底是怎么做到的呢?
首先,确定理解了在程序设计中 回文 和 子串 的含义。
回文 palindromic
正读反读都是一样的字符序列,例如:noon、level。
A word, line, verse, number, sentence, etc., reading the same backward as forward.
子串 substring
一个字符串 s 被称作另一个字符串 S 的子串,表示 s 在 S 中出现了。
A substring is a contiguous sequence of characters within a string.
最直接的解题思路我认为是:
- 遍历字符串 S 中每个字符;
- 以每个字符 S[ i ] 为中心,向两侧扩展,找到 S 所有回文子串;
- 选出最长的子串即为结果。
这个过程中,以每个字符为中心的回文子串查找,都花费了时间。
假设 S 为 xabcocbabc,它的最长回文子串应该是子串 abcocba。
在从左到右的遍历过程中,遍历到 xabco c babc 中第2个 c 时,xabcocbabc 前半段 xabco 每个字符的匹配结果都是已知状态。以字符 o 为中心的最长回文子串为 abcocba,它是回文串,那么它正反读就都一样,以 o 为中心左右对称,形象点说 o 就是面镜子,cba 是镜子里面的abc。

cba 就是 abc,cba 又不完全是 abc!你品,仔细品!有内味没有?
回到遍历中来,我们现在正遍历到 xabco c babc 中第2个 c,此时 xabcocbabc 中 abc 匹配结果已知,cba 作为“另一个” abc,是不是可以抄一抄 abc 的作业?
我们把这种情况进行抽象,并详细分析一波。如下图:

rightIndex 是当前访问到的字符中,位置最右的字符下标。特别注意,rightIndex 不是当前最长回文子串的最右字符下标! centerIndex 是一个回文子串的中心下标,这个子串最右字符下标必须是 rightIndex - 1 或 rightIndex。理解这两个变量至关重要!
i 是当前遍历到的字符下标,以 S[ i ] 为中心的匹配结束时,需要检查 rightIndex 和 centerIndex 是否需要更新。
遍历继续进行,i 来到了 centerIndex 的右侧。

以 S[centerIndex] 为中心的回文子串是左右对称的,如果 i 相对于 centerIndex 的对称点为 j :
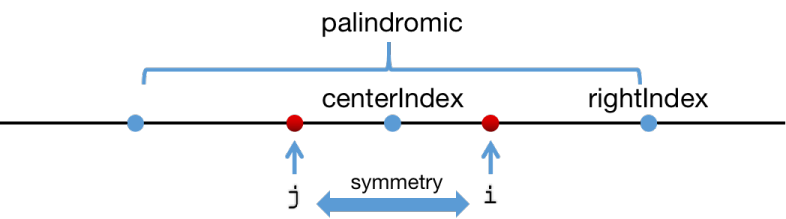
那么以 S[ j ] 为中心的回文子串必然与以 S[ i ] 为中心的回文子串对称相等。

我们的遍历是从左往右的顺序,到 i 位置的时候,j 位置的匹配结果是已知的,所以进行 i 位置的匹配时,就可以直接复用前面的匹配结果:

妙啊~~~
上面这个优化思路就是Manacher算法的核心思想,一句话总结:尽可能多复用已知的查找结果。
在Manacher算法中,引入了一个数组类型的辅助量 r,r[ i ] 表示以字符 S[ i ] 为中心的最长回文子串的半径。
1 | S: x a b c o c b a b c |
只要求得 S 对应的 r 数组,不就能知道最长回文子串了么!
PS:为什么辅助量是半径?
并不非得是半径,存直径也可,甚至存子串也可。但事情还是能简单就简单一点,通过半径 r 可以算得直径 d(d = 2 * r - 1);用中心字符下标和子串半径找到子串也是轻轻松松,重点是数字比字符串节省空间呀!
Manacher在算法中给出了 r 数组的求取公式:
r[ i ] = rightIndex > i ? min( r[ j ], rightIndex - i ) : 1
其中 j = centerIndex - ( i - centerIndex ) = 2centerIndex - i
我们来好好琢磨琢磨这个公式。
rightIndex <= i 时,在已知结果中,并没有 i 位置的对称点,所以只能重置 r[ i ] 初始值为 1,再以 S[ i ] 为中心匹配子串,最后算得 r[ i ] 结果,这个很好理解。rightIndex > i 时,为什么不能直接取 r[ j ] 的值作为 r[ i ] 的初始值呢?之前不是说 r[ i ] 可以复用 r[ j ] 的吗?
这是因为还会遇到一种情况:

此时,以 j 位置为中心的回文子串比较长,子串最左侧超出了以 centerIndex 位置为中心的回文子串的范围,超出的部分映射到 centerIndex 右侧就跑到了 rightIndex 的右侧未匹配区域,也就是图中灰色部分。所以不可以直接取 r[ j ] 的值作为 r[ i ] 的结果!
但也不是 r[ j ] 的全部不可复用,只要做一下适当裁剪就好啦!
看图可知,可复用范围最多到 rightIndex 位置,范围半径为 rightIndex - i。
取得可复用结果后,对未匹配区域就老老实实判断计算 r[ i ] 最终结果。
如果到这里,你都看得很明白,恭喜你,你已经理解了Manacher算法!🎉🎉🎉
下面我们就挽起袖子开始撸代码吧~
等等等。。。等一下!还有2个算法之外的点要稍微提一提。
- S 的长度是未知的,可能是奇数,可能是偶数。
两种情况在判断字符串是否为回文时,取对称中心的方式不太一样。
为了消除差异,一个做法是添加辅助字符,将字符串的长度统一成奇数,比如:abc –> #a#b#c#,noon –> #n#o#o#n#
如果不嫌麻烦,也可以不加辅助字符。 - 以 S[ i ] 为中轴判断轴左右两边字符是否相等的做法,可能会出现死循环。
比如:#n#o#o#n#,整个字符串满足回文,以 S[ 4 ] 为中轴时,左右两边超出边界时仍然相等,程序出现死循环。
一个做法是在字符串首再添加一个辅助字符,如:$#n#o#o#n#。
当然,也可以选择在取中轴左右两边字符时做有效判断。
1 | function longestPalindrome(str) { |